Sizhuang He
About Me
I’m a third-year Computer Science Ph.D. student at Yale University, advised by Dr. David van Dijk. Previously, I completed my Bachelor’s degree at University of Michigan, Ann Arbor, majoring in Honors Mathematics and minoring in Computer Science.
My research interests include generative modeling, LLM agents, and post-training. I have worked on discrete diffusion models that unify diffusion and autoregressive generation (CaDDi, NeurIPS 2025) and learn distributions over finite symmetric groups (Soft-Rank Diffusion, ICML 2026). I also build LLM-based multi-agent systems for automating scientific data curation at scale. Currently, I’m exploring dense, verifiable reward design for training LLM agents via reinforcement learning.
News
- [May 2026, CA]I joined Chan Zuckerberg Biohub, Inc as an AI Research Scientist Intern for Summer 2026.
- [May 2026]1 paper accepted to Journal of Computational Physics.
- [Apr 2026, Korea]2 papers accepted to ICML 2026.
- [Sep 2025, CA]1 paper accepted to NeurIPS 2025.
- [Jul 2025, BC]1 paper accepted to AI4MATH@ICML 2025.
- [Jan 2025, CT]I received the Fan Family Fellowship of Yale University.
- [Jan 2025, Singapore]1 paper accepted to ICLR 2025.
Selected Publications
-
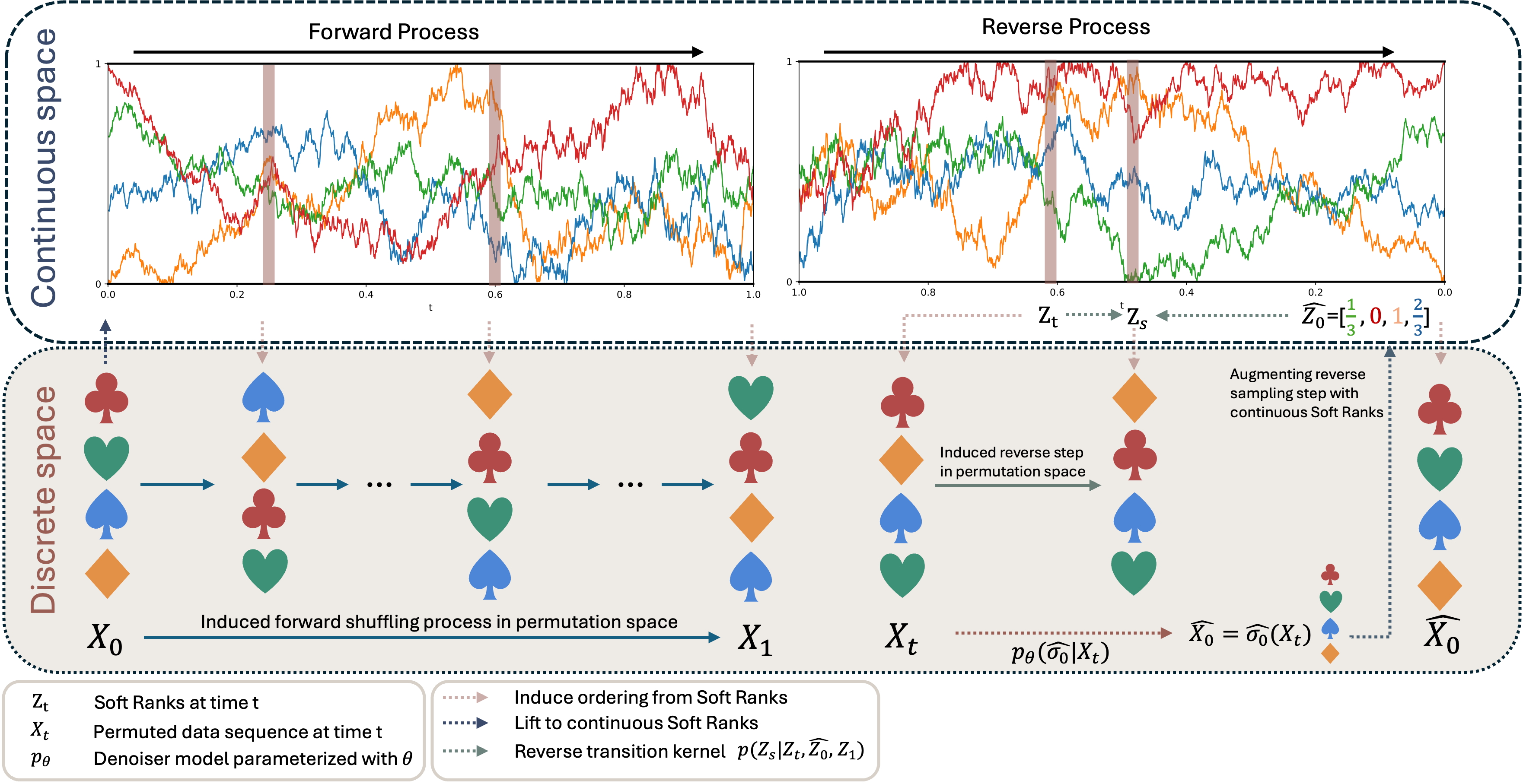 Soft-Rank DiffusionWe propose Soft-Rank Diffusion, a discrete diffusion framework for learning distributions over permutations on $S_n$, using continuous relaxed ranks and contextualized generalized Plackett–Luce (cGPL) denoisers. Soft-Rank Diffusion consistently outperforms prior baselines, with especially strong gains on long sequences. — ICML 2026
Soft-Rank DiffusionWe propose Soft-Rank Diffusion, a discrete diffusion framework for learning distributions over permutations on $S_n$, using continuous relaxed ranks and contextualized generalized Plackett–Luce (cGPL) denoisers. Soft-Rank Diffusion consistently outperforms prior baselines, with especially strong gains on long sequences. — ICML 2026 -
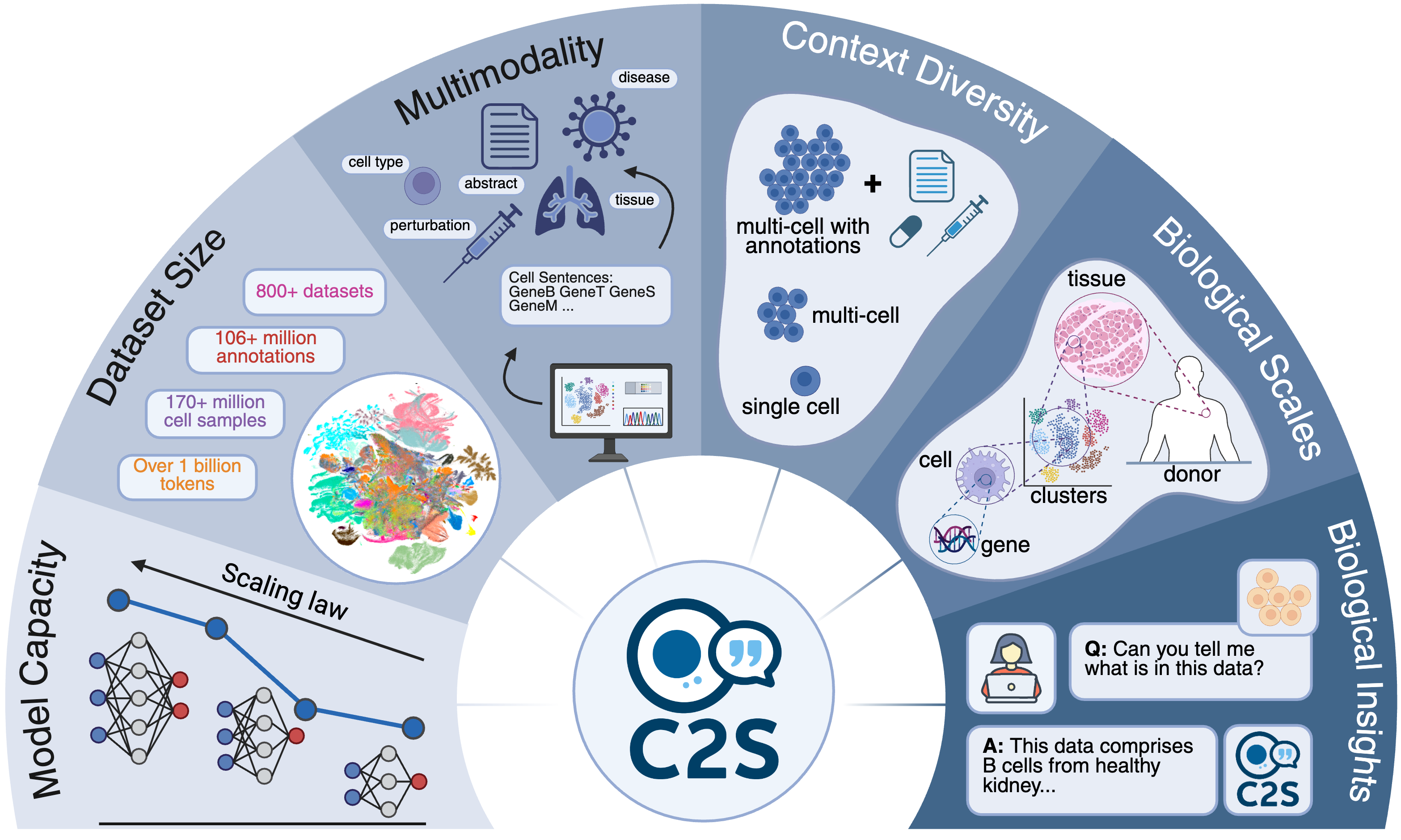
Cell2SentenceC2S-Scale scales this framework to 27 billion parameters trained on a billion-token multimodal corpus—achieving state-of-the-art predictive and generative performance for complex, multicellular analyses. Visit the project page. Read more about this work in our blog post and another blog post. — In Review
-
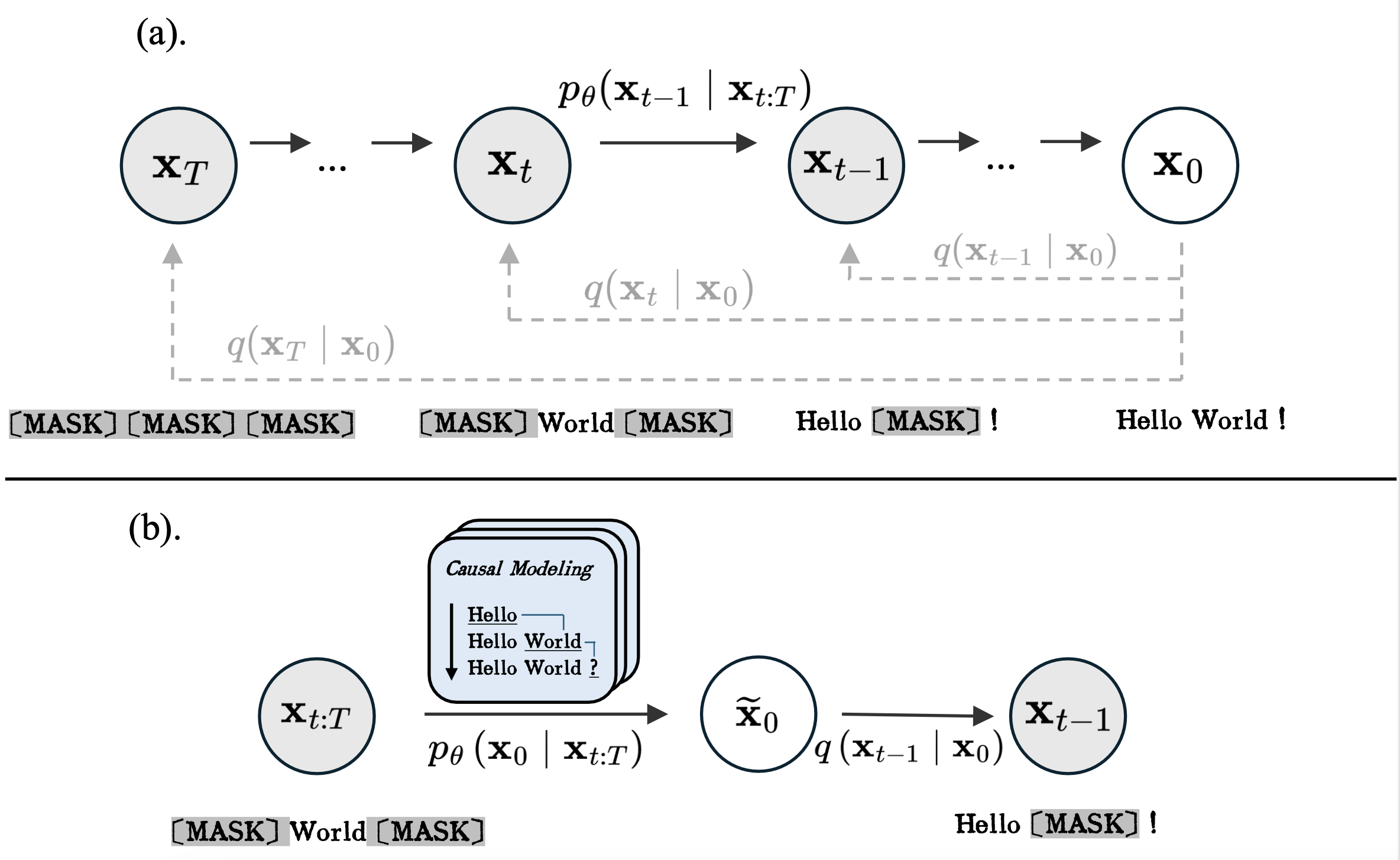 CaDDIWe introduce a novel approach to discrete diffusion models that conditions on the entire generative trajectory, thereby lifting the Markov constraint and allowing the model to revisit and improve past states. CaDDi treats standard causal language models as a special case and permits the direct reuse of pretrained LLM weights with no architectural changes. — NeurIPS 2025
CaDDIWe introduce a novel approach to discrete diffusion models that conditions on the entire generative trajectory, thereby lifting the Markov constraint and allowing the model to revisit and improve past states. CaDDi treats standard causal language models as a special case and permits the direct reuse of pretrained LLM weights with no architectural changes. — NeurIPS 2025 -
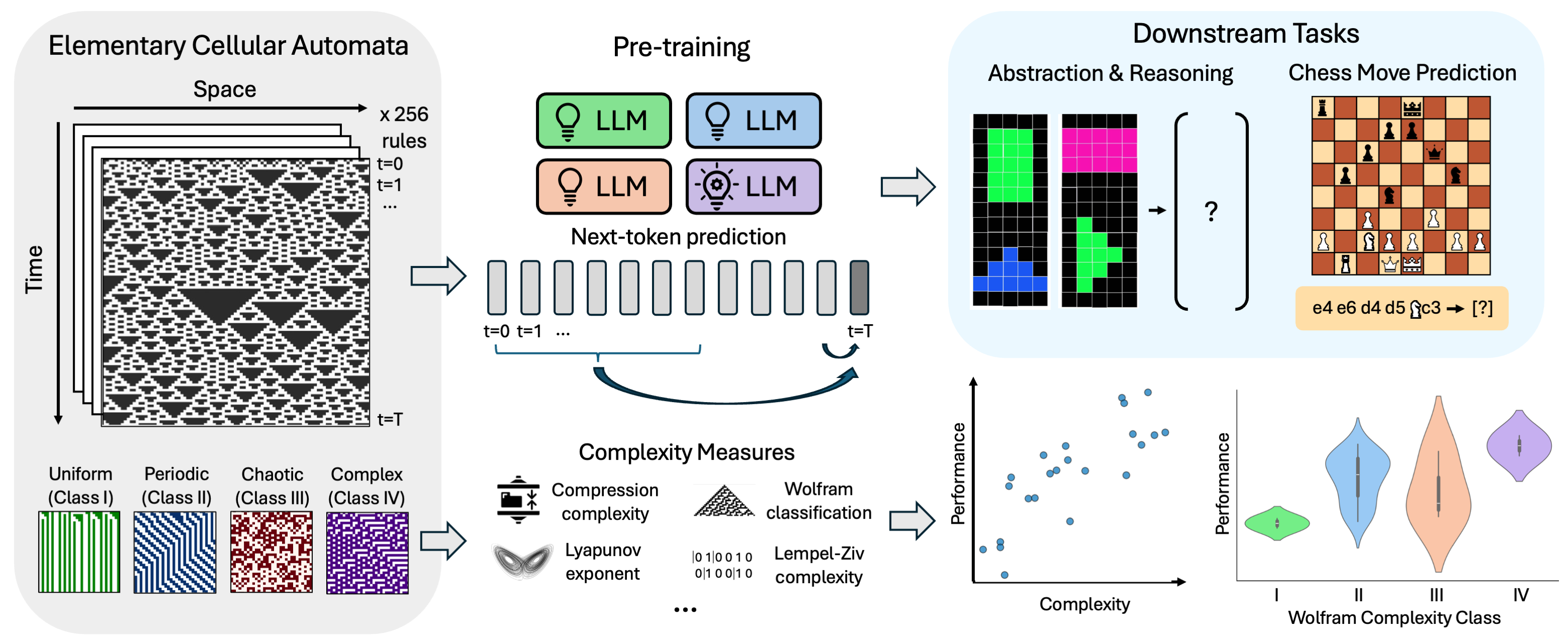
Intelligence at the Edge of ChaosBy training LLMs on elementary cellular automata rules of varying complexity, we pinpoint a ‘sweet spot’ of data complexity that maximizes downstream predictive and reasoning abilities. Our findings suggest that exposing models to appropriately complex patterns is key to unlocking emergent intelligence. — ICLR 2025
Services
Journal Reviewer
- ACM Computing Surveys
- Transactions on Machine Learning Research
Conference Reviewer
- AAAI Conference on Artificial Intelligence2027
- Conference on Neural Information Processing Systems2026
- International Conference on Machine Learning2026
- International Conference on Learning Representations2026
- AI4MATH Workshop at International Conference on Machine Learning2025
Powered by Jekyll and Minimal Light theme.